A practical project I designed to introduce developers to a great solution that efficiently scales job consumers based on the number of jobs in the queue that were sent by job pushers. A pattern common in applications that stream real-time events and need them processed asynchronously.
I discovered KEDA while working at Manafa Crowdfunding where we were handling a Laravel application which was caching jobs to a Redis cache and using workers to process the jobs. We needed a way to consume these jobs efficiently and in a cloud-native way, because traffic was inconsistent to provision some n number of pods to consume these jobs.
Approach
So, I researched the topic and ended up at KEDA - which provides scalers, which are Kubernetes CRDs, for all types of databases. These scalers can be used to target a workload - say a Deployment of the workers - using scaleTargetRef to scale based on a query you supply next in triggers.
The triggers contain specifications on what information triggers a scaling action. For example, a simple query which returns a number: SELECT COUNT(\*) FROM jobs_queue WHERE status = 'pending' OR status = 'failed'; is enough for KEDA to work with. Then, you specify a queryValue: a value you want to scale on.
Of course, to query a database, you need to authenticate! Enter the TriggerAuthentication CRD provided by KEDA, which uses a Secret object to authenticate the trigger.
You can customize much more - things like scaling behavior, query frequency, and scaling cooldown. Under the hood, KEDA creates a HorizontalPodAutoscaler that scales based on the queryValue rather than on CPU or Memory utilization.
Architectural Design
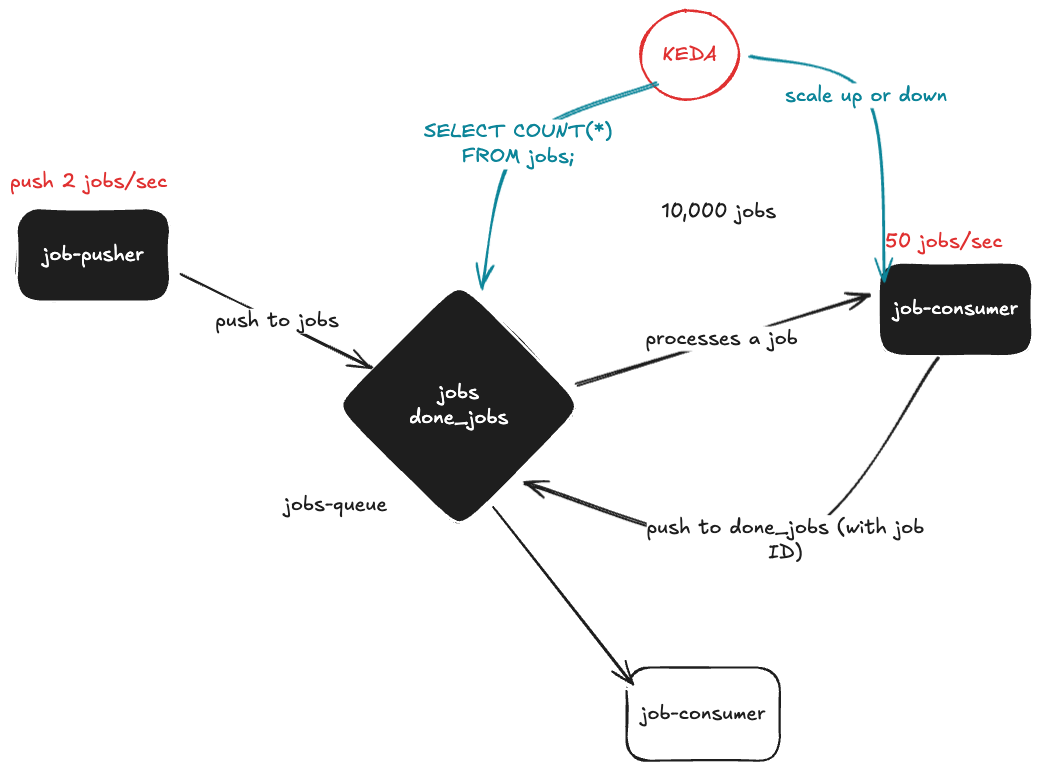
Architectural Diagram
The architecture is simple. We have two processes: A job pusher and a job consumer. Between them, we have a database with two tables: jobs, and done_jobs
Job Pusher
with psycopg2.connect(**DB_CONFIG)as conn:with conn.cursor()as cur: payload =''.join(random.choices(string.ascii_letters, k=20)) cur.execute("INSERT INTO jobs (payload) VALUES (%s)",(payload,)) conn.commit()print(f"Pushed job with payload: {payload}")time.sleep(random.uniform(1,3))
job-pusher pushes a "fake" job to the jobs queue with a random delay of [1,3] seconds, indefinitely.
Job Consumer
with psycopg2.connect(**DB_CONFIG)as conn:with conn.cursor()as cur:# Fetch and lock a job cur.execute("""
DELETE FROM jobs
WHERE id = (
SELECT id FROM jobs
ORDER BY created_at
LIMIT 1
FOR UPDATE SKIP LOCKED
)
RETURNING id, payload
""") job = cur.fetchone()if job: job_id, payload = job
print(f"[{pod_name}] Processing job {job_id}: {payload}")# Simulate random processing time (2-10 seconds) process_time = random.uniform(2,10) time.sleep(process_time)# Mark as done cur.execute("INSERT INTO done_jobs (id) VALUES (%s)",(job_id,)) conn.commit()print(f"[{pod_name}] Completed job {job_id} in {process_time:.2f}s")else: time.sleep(1)
job-consumers watch poll the jobs table and takes a single job - that job is LOCKED, so it can't be consumed by other consumers and then stored. A random processing time [2,10]is added. Then, that job is added to the done_jobs table. This process repeats with no stop.
A ScaledObject targets our consumer deployment (scaleTargetRef.name: job-consumer). We'll scale the number of consumers based on the number of jobs currently in the jobs table. We can see that our scaler has a minReplicaCount: 1 and maxReplicaCount: 20, meaning we'll scale up to 20 pods, if needed. We'll run the query every 15 seconds (pollingInterval: 15), and after a scaling action, whether up or down, we'll wait 30 seconds before scaling again (cooldownPeriod: 30).
Next, we look at the Trigger section. Our trigger runs a query that counts the number of jobs, and for every 5 jobs, we perform one scaling action. However, if we're going from 0 -> N OR going down from N -> 0, the activationQueryValue is considered. See more: Activating and Scaling thresholds
Simply, the object references a secret named postgres-secret and uses it to fill the connection parameter in the ScaledObject
This is the secret used in this case:
apiVersion: v1
kind: Secret
metadata:name: postgres-secret
namespace: job-processing
type: Opaque
stringData:# "key" refers to this connectionconnection:"postgresql://jobuser:jobpass123@postgres.job-processing.svc.cluster.local:5432/jobqueue?sslmode=disable"
Key Outcomes
Simple project yet one that solves a real-world production problem. Perfect for a DevOps Engineer portfolio!
Kustomize-ready; one command to apply. kubectl kustomize . on the root project directory! Works on any Kubernetes cluster with KEDA and CRDs installed. Deploying KEDA