(2025-10-30) Major Update: Deploying to Kubernetes
Frontend look
I was sponsored by Saudi Digital Academy (SDA) to attend a 3-month DevOps & Cloud Computing Bootcamp conducted by IronHack (IronHack's version of the bootcamp). In it, I improved my skills in Bash scripting, Linux, GitOps, Azure, Ansible, Terraform, Kubernetes, and more. As part of the final project, we were given the task of deploying a three-tier application onto a Kubernetes Cluster (Azure Kubernetes Service). The application code was provided to us, but I chose to deploy this app instead.
Catus Locatus is a lost pet finding app. Announce a pet you lost by showing others where it was lost. Other people can contact you if they find your pet! All pets are drawn on top of a Leaflet map, with dog/cat emojis for easier searching. The website only accepts coordinates of your current location, to reduce the number of false reports.
My Role
My role in this project was more of a leading role than a developer. I still worked and developed alongside the team, but I was the one handling meetings and deadlines. I was also the repo owner so I set the main branch protections and on-PR checks using GitHub Actions. I took care of the more complex tasks, as well as designing the system architecture and the Kubernetes cluster.
Approach
NOTE: I mentioned that we worked on this as a team, but the preceding week I worked on the entire project from scratch, just because I knew I was going to lead it so it was nice knowing what we were up against early on so I can prepare. So here when I mention I "wrote/built/developed/verbed" something, I'm referring to my early implementation of the project.
I began on creating a backend, because in my original project I was using supabase, which is a platform that provides you with a database and an API to go alongside it. Their free tier was generous, so I had no issues with that. But for this implementation, I needed a decoupled backend to work alongside the frontend. After building the backend in expressjs, I began writing the Dockerfiles.
Containerization
Nothing fancy here, just a multi-stage build of a containerized app. The frontend image was a React app, so I simply built it and used an Nginx base image with an nginx.conf. Final image size was 58MB. Cool. The backend was Express.js, with the usual middleware. The image ended up being 140MB. A bit high for my liking but not too bad. The two images are hosted on Azure Container Registry.
Kubernetes
For Kubernetes, we had a choice on how to deliver the resources for it, because we were also going to use Terraform, and it has a Kubernetes provider already. I decided that if a resource makes more sense to create via Terraform, then we'd do it there. Otherwise, just write the YAML for it since it was quicker probably. Things like Kubernetes Secrets and ConfigMaps made more sense to write in Terraform, because the secrets were values you could get from the resources provisioned by Terraform's AzureRM provider, so it was better to store references to resources rather than hardcode the secret values in a YAML manifest for a Secret.
Additionally, I chose to go with the Helm provider as well, to install needed Helm Charts such as External-DNS, Cert-Manager, and Nginx-Ingress.
The folder structure looked like this:
ali@Ali:~/catus-locatus-k8s/k8s$ tree ..├── backend
├── frontend
├── monitoring
└── networking
Backend and frontend contained deployments and HPAs, the monitoring folder container deployments, configmaps, and services for Grafana and Prometheus, and the networking folder contained clusterIPs and an Nginx Ingress Controller.
Terraform
Our main Infrastructure-as-Code tool. Since the domain we were using (this same one you're on!) is on AWS Route 53, we used the AWS provider. AzureRM worked well for Azure resources, and like mentioned before, Kubernetes and Helm providers were also used. I wrote the resource files in Module Pattern.
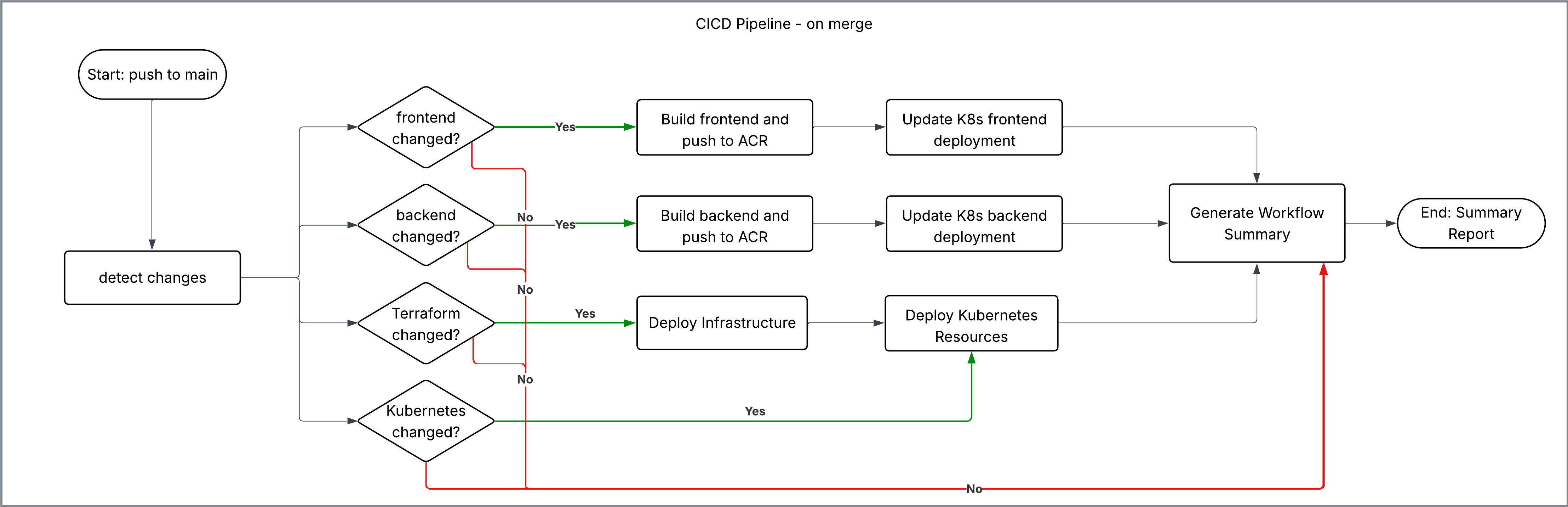
For pipelines, I wrote them for Github Actions. I used a master workflow pattern, where only one workflow would be triggered on-push, and it would then run other workflows based on the changes made in the commit. This proved efficient because when making changes to the backend code, only the backend image would be rebuilt, eliminating unnecessary creation of images for the frontend.
Teamwork and Project Management
To manage tasks, we used Trello boards to keep track of tasks. Trello proved a nice and quick way of writing To-Dos and attributing them to a person.
Trello boards to divide tasks
From Trello cards, we derived User Stories and wrote them in GitHub Issues. From these Issues, we'd begin working on them and then eventually submit a Pull Request, referencing the Issue we're solving. This was a great system and it kept track of changes well.
System Design
Azure
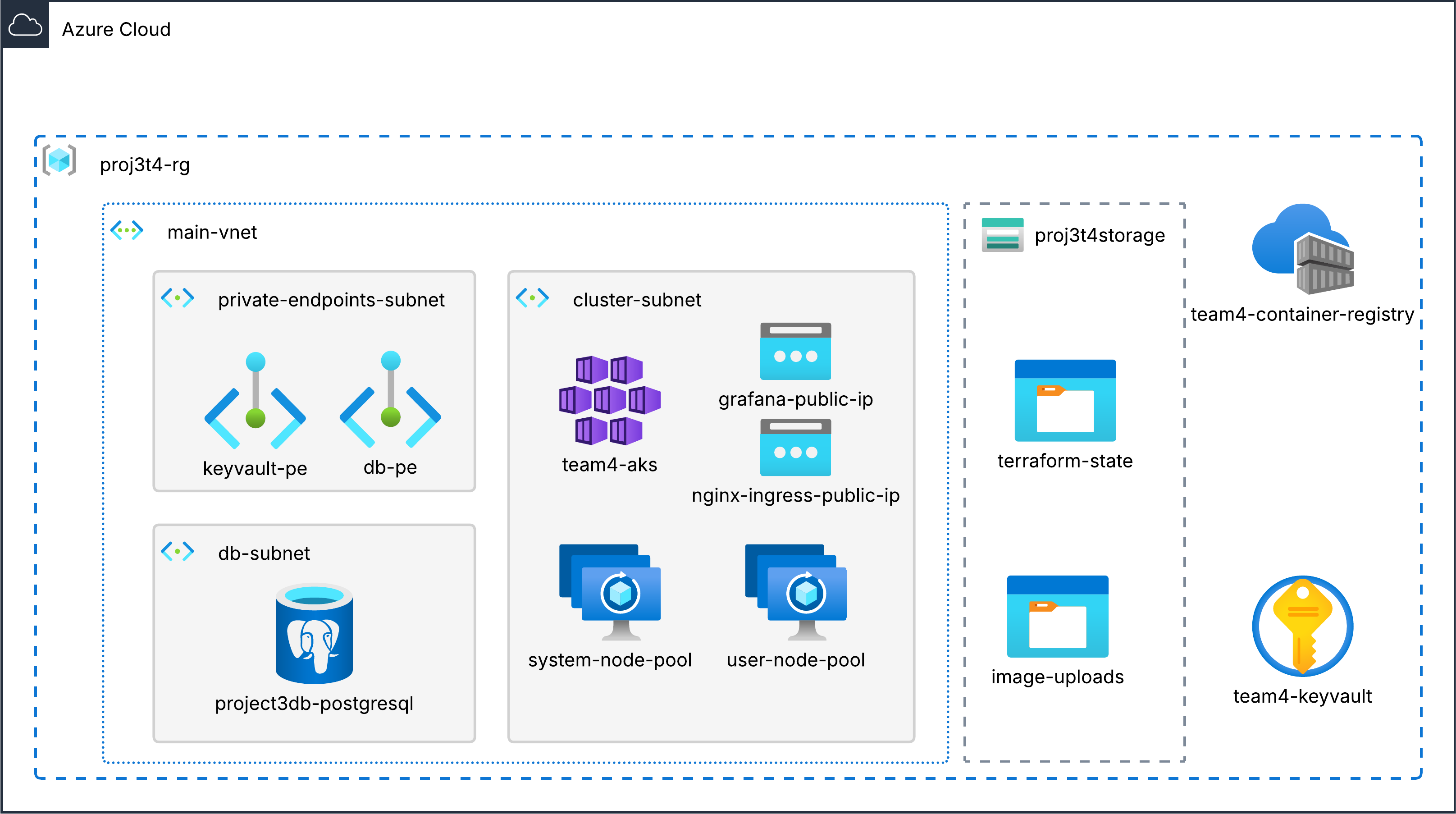
Azure is the main cloud provider we've been using throughout the bootcamp. Let's take a look at the resources deployed on it for this project!
Azure system, showing a resource group containing a Vnet, a storage account, an ACR, and a Key Vault
Nothing unusual. I'm using PostgreSQL because the original Catus Locatus uses Supabase which uses PostgreSQL for its flavor of SQL :-)
We're using a storage account with two containers - one for storing Terraform's .tfstate file (private), and the other for storing user uploads. (public)
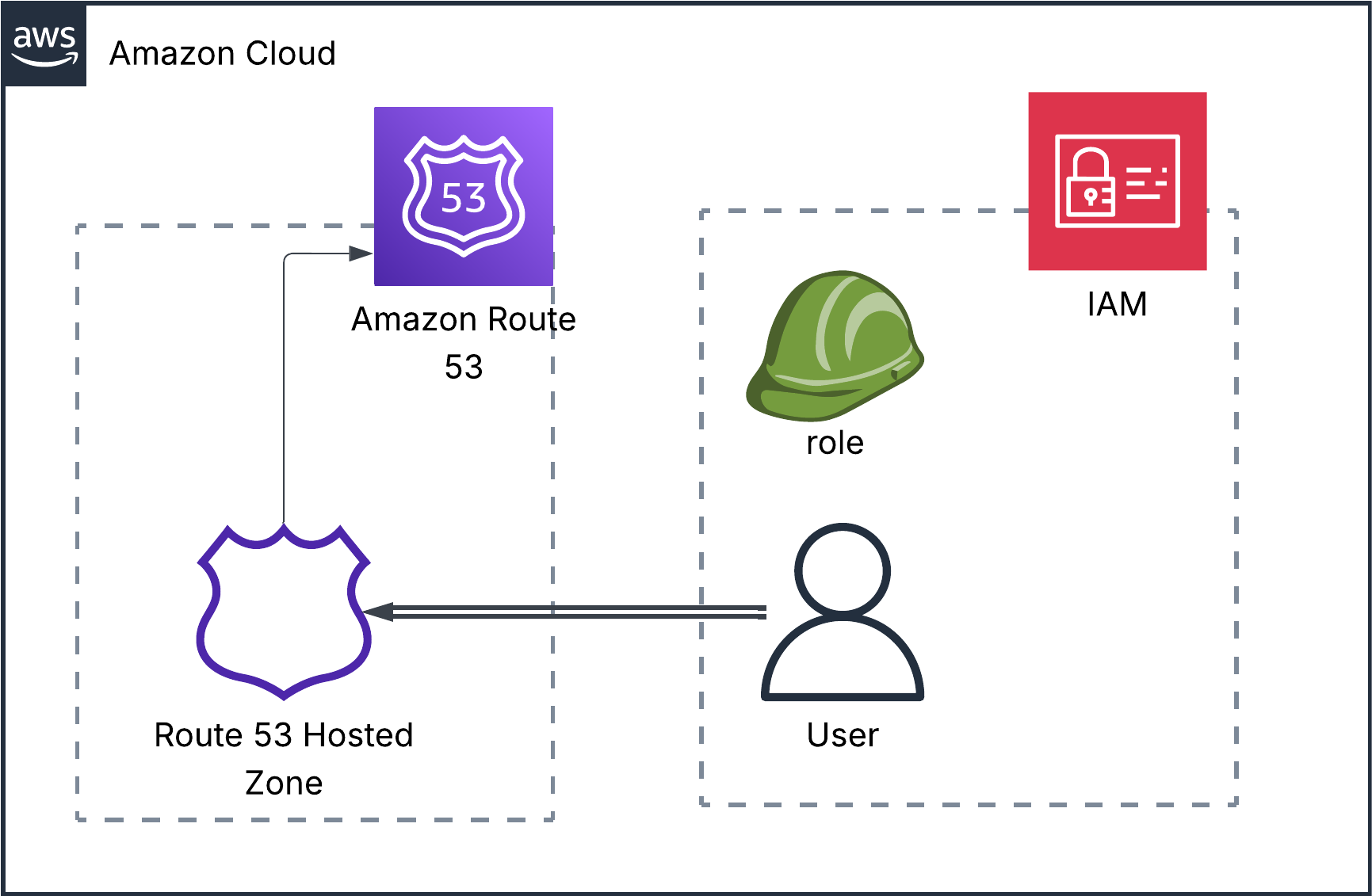
AWS
The reason why I'm using AWS here is because my domain is managed in AWS Route 53, so I decided to incorporate a bit of multi-cloud flair into the project :P
Again, nothing too fancy. We'll use the domain's Hosted Zone, and to manage the DNS records on it I created an IAM User that has access to ONLY the hosted zone. Principle of Least Privilege, anyone?
Here's the Terraform code for the policy attached to the user:
resource "aws_iam_policy""external_dns"{name="external-dns-policy"description="Allow external-dns on K8s to manage Route 53 records"policy= jsonencode({Version="2012-10-17"Statement=[{Effect="Allow"Action=["route53:ChangeResourceRecordSets"]Resource="arn:aws:route53:::hostedzone/${var.aws_r53_zone_id}"},
{Effect="Allow"Action=["route53:ListHostedZones",
"route53:ListResourceRecordSets",
"route53:GetChange"]Resource="*"}]})
}
Kubernetes
The star of the show! This is my first project using Kubernetes, and I have to say: I absolutely love it. Coming into the bootcamp, Ansible and Kubernetes were the two technologies I was looking forward to learning the most. And they both did not disappoint!
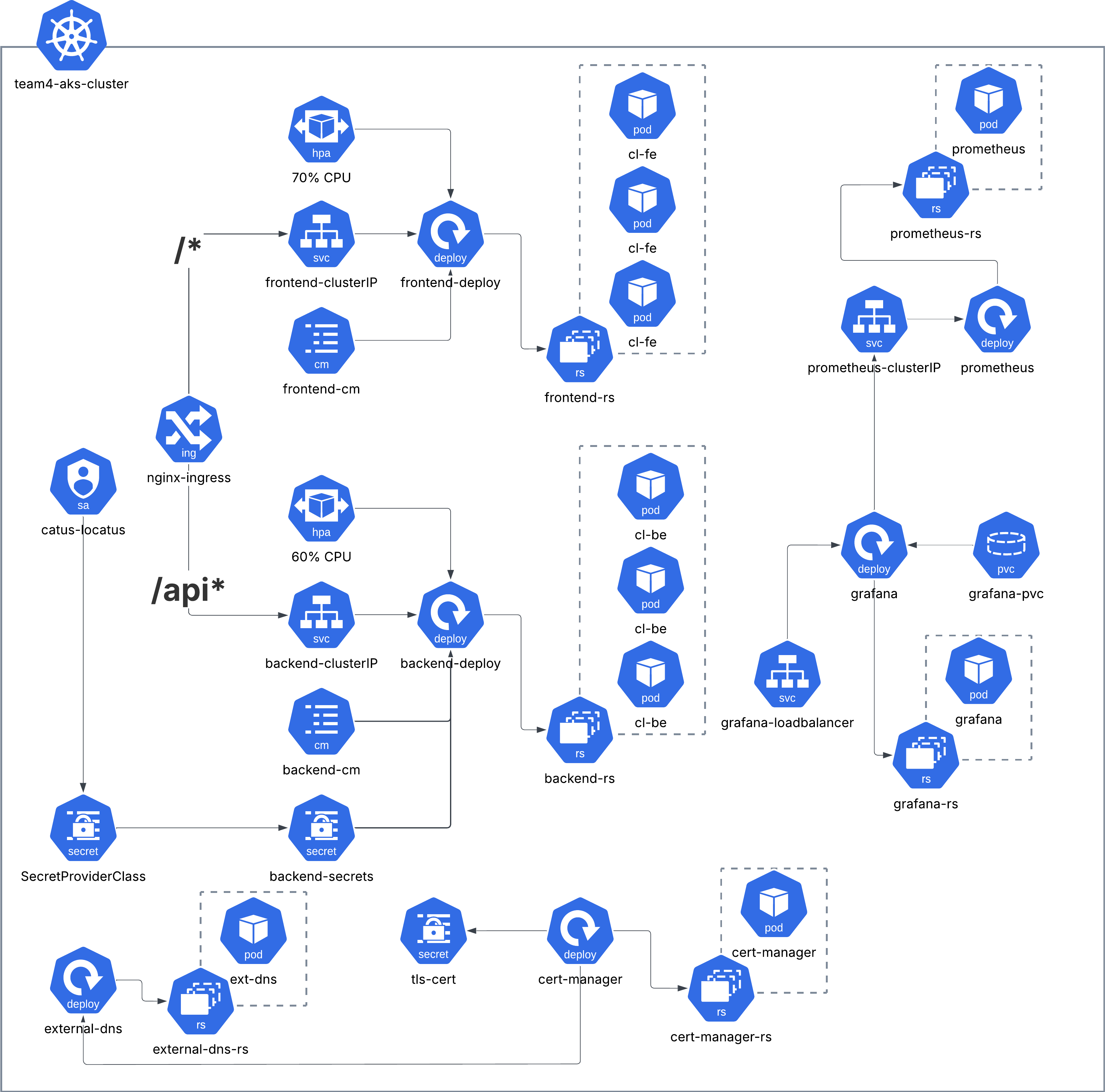
A cool looking cluster! At the heart of it, we have an nginx-ingress, directing traffic using the request's path.
/* takes you to the frontend ClusterIP, where a deployment with replicas=3 is being monitored by a HorizontalPodAutoscaler that is set to scale up on 70%CPUUtilization, with minReplicas=3 and maxReplicas=15. (Our tests later showed that 15 maybe a bit high?) Lastly there's a ConfigMap for the frontend with an optional ENV variable.
/api* in the other hand takes you to the backend deployment's ClusterIP, the deployment holds similar parameters and accompanying resources as the frontend, but they differ in that the backend also has a K8s Secret resource. The Secret contains database authentication information, as well as the Azure Storage Container connection string for connectiong to the user uploads container. These secrets are obtained from Azure Key Vault, which has an access policy to allow the user-assigned identity of the application to access its secrets using a ServiceAccount, that helps a SecretProviderClass get these secrets using the Secret Store CSI Driver.
Then, we have the monitoring stack: Prometheus and Grafana. Nothing special to mention here: We mount the Grafana deployment with two ConfigMaps - One to enable the default data source to point at our app's metrics, and the other to mount the dashboard JSON file.
Lastly, to manage the DNS records on AWS and sync them with the Ingress' public IP, we're using external-dns, and for TLS termination, we're adding cert-manager.
Now, let's see how this all ties together!
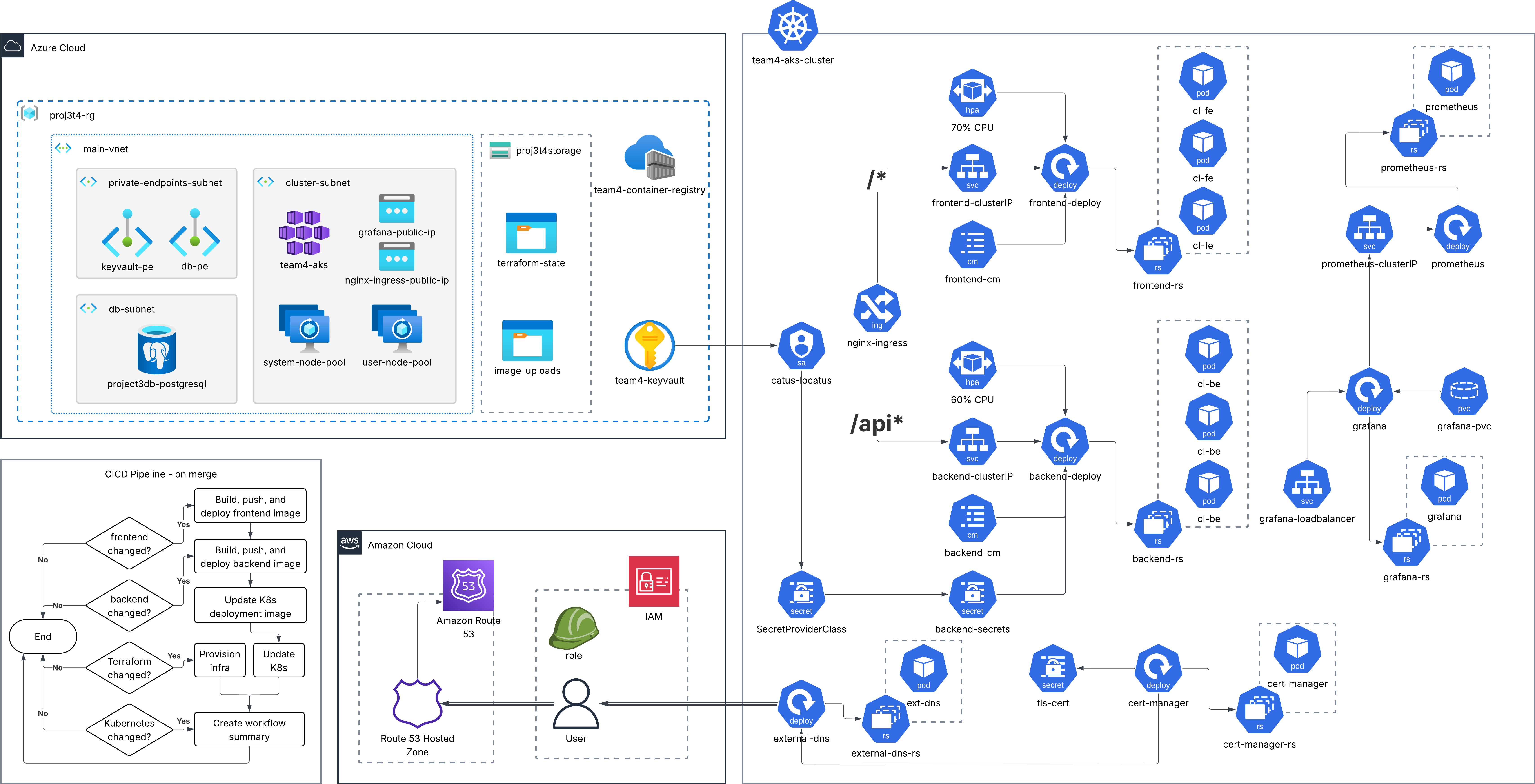
The Full System Architecture
The main points are how Azure Key Vault allows the Service Account to connect, and how external-dns accesses my AWS account via an IAM User.
Observability and Monitoring
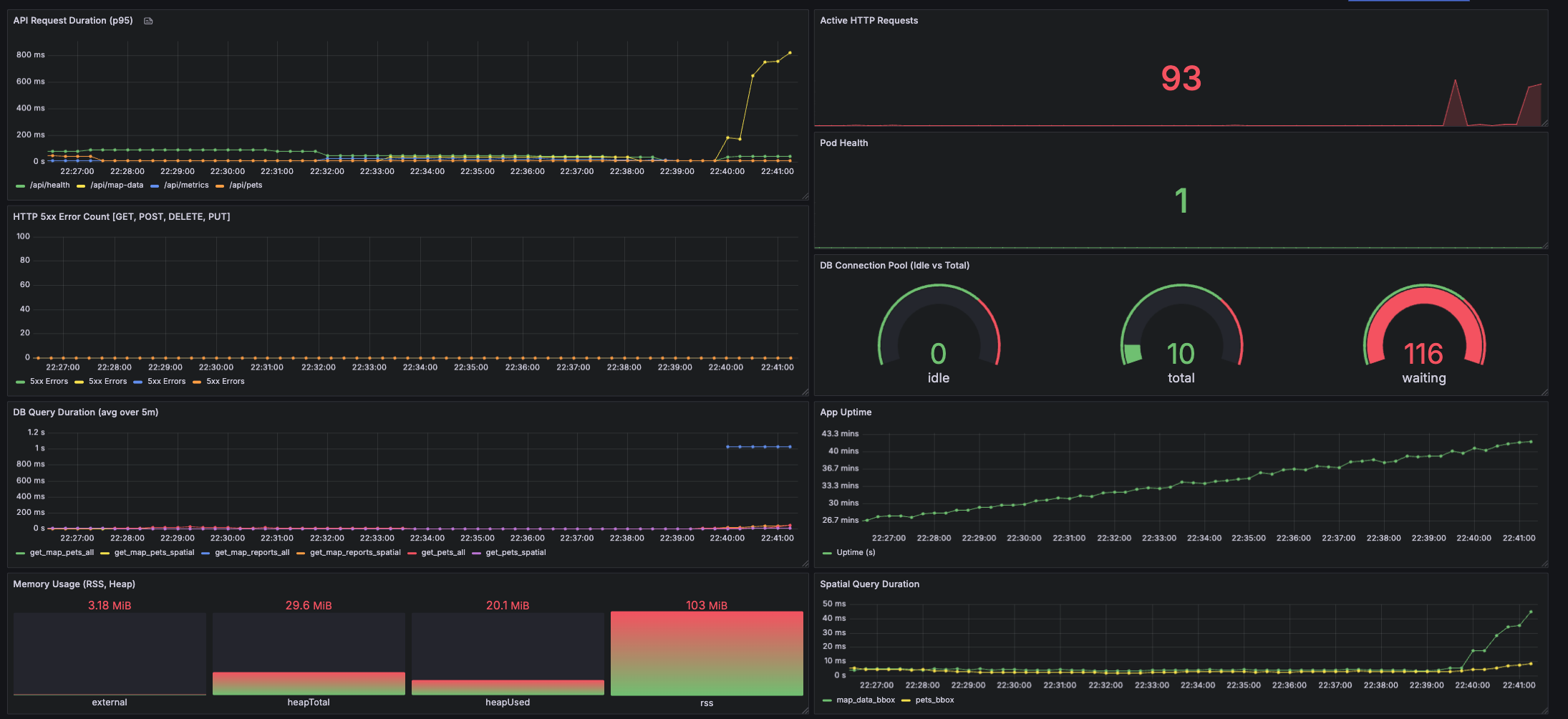
We used application-focused metrics to supply Prometheus with the data. I wrapped database queries with a function to track query times, and used Middleware for others for HTTP requests metrics. This was all done using the help of prom-client!
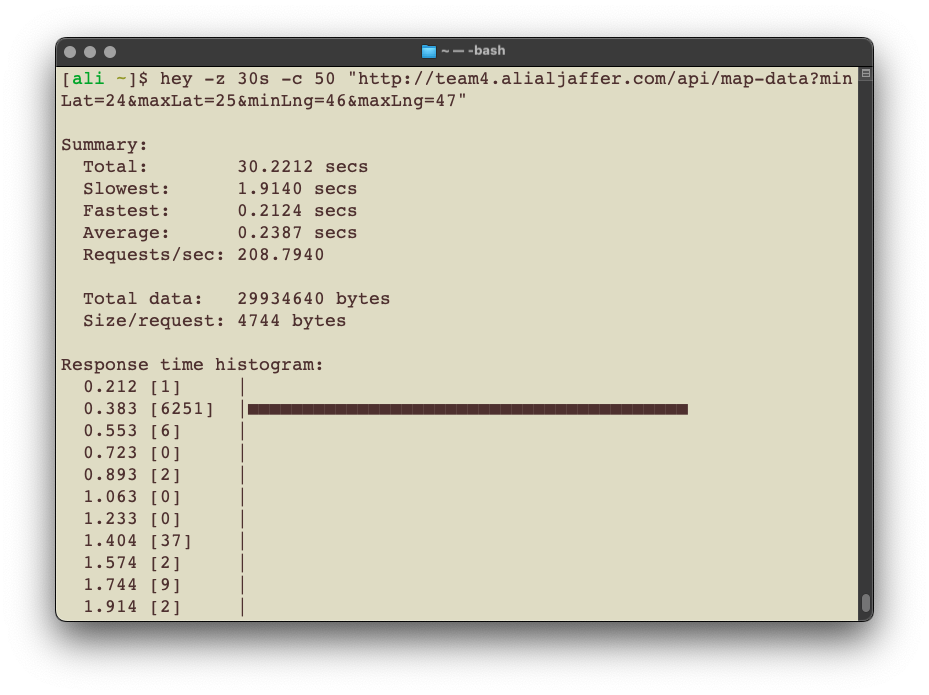
This dashboard immediately proved its efficiency because during load-testing, I noticed that 10 Max Connections allowed in the connection pool were way too low for even moderate traffic. The timeout was at 10 seconds and I found that to be OK.
Security Measures
Permissions: As mentioned before, Principle of Least Privilege was used generously here. Maybe except in the Key Vault access policies, where we had issues with Terraform destroying and recreating the Key Vault on every terraform plan, even when no changes occurred?
Containers: For containers, we used Multi-Stage Dockerfiles, with versioned images to guarantee consistency. Moreover, we also hardened the image security by creating a user with limited permissions. See the Dockerfile for the frontend below!
Public Access: We limited public access to resources that absolutely needed public access, and utilized Private Endpoints for services that needed it. We did not have time to apply this to ALL resources, but we tried our best. Maybe given more time we'd be able to harden this further!
Outcomes
Extremely satisfied with the outcome of this project. Really believe it's an eye-opener to Production-ready development, architecting, and deployment.
TLS/SSL Termination with Ease: Using external-dns and cert-manager, we achieved an automated process with TLS certificate issuance. It was my first time implementing the two, so it was a bit of a challenge, but now I know what to do for my next project :D
Rolling updates: Both of our two deployments run rolling updates strategy, ensuring there's NO DOWNTIME on new version deployments!
Fully automated infrastructure: Thanks to Terraform, we could delete and recreate this entire infrastructure in MINUTES! All the resources in the system diagrams above are created via Terraform and Github Actions Workflows.
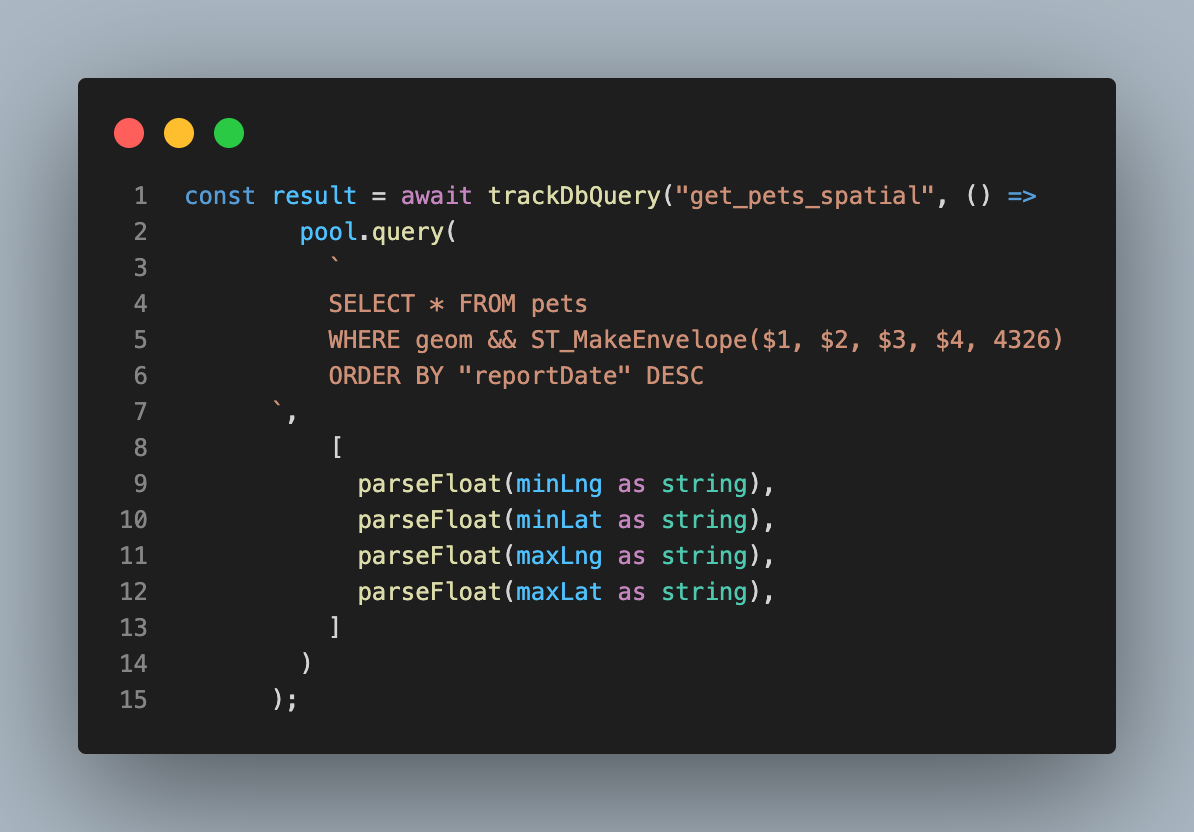
Spatial Queries: This is more of a fullstack development feature rather than a DevOps one, but in the backend, since we're using a Map-focused app, I utilized spatial queries with PostgreSQL's POSTGIS extension! It did WONDERS for query times!
Spatial query using the POSTGIS extension
Challenges
Setting up external-dns with cert-manager was easy in hindsight, but it was a tough task. But nothing a bit of Googling and YouTubing can't fix! :) Glad I got it done.
We had an Azure-Subscription-Wide problem where AKS clusters would be so unreliable to provision, getting a 400 Bad Request error with NO MESSAGE describing the error itself. We had to try various region-SKU combinations to just get it to provision. Definitely slowed us down. I solved this TEMPORARILY by setting the lifecycle of the AKS resource on Terraform prevent_destroy = true
Another challenge was the Access Policy issue of being deleted from the Key Vault. Every few hours the Key Vault's access policies would be wiped out for some reason. Still no fix, but I created a Bash script that just recreated them using Azure CLI instead of manually doing it every time.
What Could Improve
Using RBAC instead of Access Policies for Key Vault.
We have a Github Action that pushes new backend/frontend images on PR if any of the source code for them changes. Right now it pushes to the tag latest which is bad, I should've changed it to something like testing or dev, then have it deploy alongside the production deployment.
Restrict access to ACR: Maybe using RBAC or private endpoints? But Private Endpoint may not be ideal if using Github.
Conclusions
Super proud of this project and the team! We worked on this for four days, Sunday to Wednesday. Been fun managing a team and a project that is this exciting. Can't wait for the next one!